자료구조 - 그래프
자료구조를 공부하는 이유 중 하나는, 상황에 맞는 방식으로 데이터를 저장하고 사용하기 위해서이다. 데이터 사이에 어떤 관계가 있는지에 따라 적절한 자료구조를 골라서 사용해야 한다. 예를 들어 앞과 뒤라는 관계를 저장하고 싶으면 배열이나 링크드 리스트같은 선형적 자료구조를 쓰면 되고, 위와 아래라는 관계를 저장하고 싶으면 트리같은 계층적 자료구조를 쓰면 된다. 이러한 다양한 목적 중 그래프는 연결 관계를 표현하기 위해 사용된다.

예시로는 위치 데이터, 사회 연결망(페이스북 내 친구 관계 등) 등이 있다.
실생활에서도 다양한 연결 관계가 나타난다.
- 통신: 수많은 컴퓨터들의 연결 관계인 인터넷
- 생물: 유전자와 단백질의 상호 작용 관계
이것들 뿐만 아니라, 세상에는 무궁무진한 연결 관계들이 있다. 이러한 연결 관계를 그래프를 통해 나타낼 수 있는 것이다.
그래프 기본 용어
친구 관계를 예시로 기본 개념들을 알아보자.
링크드 리스트 노드 같은 경우는, 데이터들 사이에 레퍼런스를 통해서 선형적인 관계를 만들었다. 그래프도 노드라는 기본적인 단위를 사용한다.
A와 B라는 두 노드 사이에 연결 관계가 형성된 경우, (A, B), (B, A)라는 두 개의 엣지가 생성된다. 두 노드가 엣지로 연결돼있는 경우 서로 인접해 있다고 한다. 엣지가 없는 경우 서로 인접해있지 않다고 한다.
A와 B는 서로 연결돼있지 않지만, 둘 다 C와 각각 인접해있는 경우 A-C-B 경로, 혹은 B-C-A 경로가 있다고 할 수 있다. 이 경로 사이의 거리는 2이다.
두 노드 사이에 있을 수 있는 경로들 중 가장 거리가 짧은 경로를 최단 경로라고 한다. 특정 노드에서 다시 그 노드로 돌아오는 경로는 싸이클이라고 한다. (A-B-C-D-A)
한 노드가 갖고 있는 엣지의 수를 차수라고 한다. A가 B, C와 연결돼있을 경우 A의 차수는 2이다. 차수를 이용하면 유용한 데이터를 알 수 있다. 친구 관계를 예시로 들 경우, 누가 몇 명의 친구가 있는 지를 알 수 있는 것이다.
방향 그래프
엣지가 쌍방향이면 방향이 없다고 얘기할 수도 있다. 이를 무방향 그래프(undirected graph)라고 한다. 반면에 방향성을 갖는 그래프도 있다. 방향 그래프에서는 엣지가 떠나는 노드를 항상 앞에 쓰고, 엣지가 향하는 노드를 뒤에 쓴다.
ex) A에서 B로 향하는 방향 그래프의 경우, 엣지는 (A, B)이다.
방향성이 있다고 해서 쌍방향이 불가능한 건 아니다. 인스타그램에서 맞팔을 할 수 있듯이 말이다.
방향 그래프는 무방향 그래프와 차이가 있다.
우선 경로의 차이가 있다. 예를 들어 A -> B, A -> C인 경우 쌍방향이 아니므로 B에서 A로의 방향이 없다. 따라서 B에서 C로 갈 수 있는 경로는 없는 것이다.
그리고, 차수의 차이 또한 있다. 노드에서 나가는 엣지의 수를 출력 차수, 노드로 들어오는 엣지의 수를 입력 차수라고 한다.
가중치 그래프

인천-LA행 비행 시간, LA-뉴욕행 비행 시간, 뉴욕-인천행 시간이 다 다르므로 이걸 똑같이 연결해줄 순 없다. 이런 상황에선 엣지에 특정 숫자 값을 지정해줄 수 있는 가중치 그래프를 사용한다.
가중치 그래프에서는 인천-LA: 가중치 9, LA-뉴욕: 가중치 5, 뉴욕-인천: 가중치 13 이런 식으로 가중치를 표기해줄 수 있다.
가중치 그래프를 사용할 경우 경로의 거리 개념이 좀 바뀐다. 무가중치 그래프에서 거리는 단순히 경로에 있는 엣지의 수였는데, 가중치 그래프에서 거리는 경로에 있는 모든 엣지 가중치의 합이다. 따라서,
가중치 그래프 인천-LA-뉴욕 경로 거리: 9 + 5 = 14가 된다.
이는 무가중치 그래프 인천-LA-뉴욕 경로 거리인 1 + 1 = 2와는 차이가 있다.
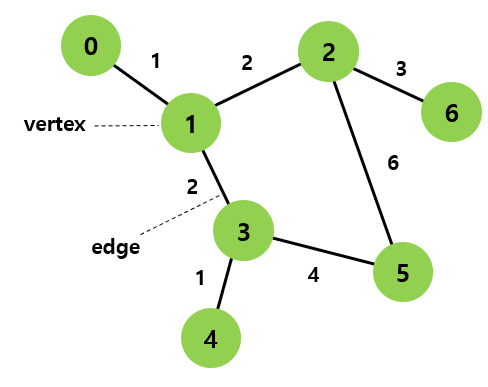
그래프 기본 용어

노드: 그래프에서 하나의 데이터 단위를 나타내는 객체이다. SNS 그래프에서는 하나의 유저가 하나의 노드이다. 위 그래프에서는 노란색 원이 노드를 나타낸다.
엣지: 그래프에서 두 노드의 직접적인 연결 데이터이다. 예를 들어, 페이스북 유저 그래프에서는 두 유저의 친구 관계에 해당하는 데이터이다. 위 이미지에서는 흰 선들이 그래프의 엣지에 해당한다. 두 노드 사이에 엣지가 있을 때, "두 노드는 인접해 있다"라고 표현한다. 엣지가 갖는 특성에 따라 그래프의 종류가 나뉘기도 한다:
- 방향 그래프(directed graph): 방향 그래프에서는 엣지들이 방향을 갖는다. 인스타그램의 팔로우 관계처럼 한 유저가 다른 유저를 팔로우하는 일방적인 관계를 나타낼 수 있게 해준다.
- 가중치 그래프(weighted graph): 가중치 그래프에서는 엣지들이 연결 관계뿐만 아니라 어떤 정보를 나타내는 수치를 갖는다. 그 정보는 예를 들자면 친구 관계라면 '친밀도', 위치 정보 그래프라면 '두 장소의 거리'같은 것이다.
차수: 하나의 노드에 연결된 엣지들의 수이다.
- 무방향 그래프에서는 하나의 노드에 연결된 엣지들의 수를 나타내고, 방향 그래프에서는 노드를 떠나는 엣지의 수를 출력 차수, 노드에 들어오는 엣지의 수를 입력 차수로 구별해서 부른다.
- 위 그래프에서 현승 노드의 차수는 3, 영훈 노드의 차수는 2이다.
경로: 한 노드에서 다른 노드까지 가는 길. 지웅 노드와 규리 노드는 서로 인접해 있지 않은데, 그래도 지웅 노드에서 규리 노드로 갈 수 없는 건 아니다. 지금 지웅과 규리는 둘 다 소원 노드와 친구이다. 그래서
지웅 - 소원 - 규리이 길을 따라가면 지웅 노드에서 규리 노드로 갈 수 있다.지웅 - 소원 - 규리이 길을 경로라고 한다.- 경로의 거리
- 비가중치 그래프: 한 경로에 있는 엣지의 수
- 가중치 그래프: 한 경로에 있는 엣지의 가중치의 합
- 최단 경로: 두 노드 사이의 경로 중 거리가 가장 짧은 경로
- 사이클: 한 노드에서 시작해서 같은 노드로 돌아오는 경로
- 경로의 거리
연결된 그래프
그래프는 여러 개의 노드와 엣지를 갖는데, 그렇다고 해서 그래프 안에 있는 모든 노드들이 서로 경로를 통해 연결될 필요는 없다.
SNS 유저 그래프를 만든다고 생각해보자. 세상의 모든 유저들이 서로 어떻게든 꼭 연결되어 있는 건 아니다.
그래서 아래 그림처럼 서로 연결된 노드들이, 서로 나눠져 있을 수도 있다. 보기에는 2개의 무리로 나눠져 있지만 어쨌든 하나의 SNS 유저 그래프라고 할 수 있다.

조금 더 극단적인 예시를 보면 심지어 이렇게 아예 엣지가 없고 노드만 있는 그래프들도 있을 수 있다.

그래프 노드 구현
그래프 노드를 파이썬으로 구현해 볼 차례이다. 지하철 역을 예시로 해 보자.
GraphNode.py
class StationNode:
"""지하철 역 노드를 나타내는 클래스"""
def __init__(self, name, num_exits):
self.name = name
self.num_exits = num_exits # 출구개수
# 지하철 역 노드 인스턴스 생성
station_0 = StationNode("교대역", 14)
station_1 = StationNode("사당역", 14)
station_2 = StationNode("종로3가역", 14)
station_3 = StationNode("서울역", 14)
# 노드들을 파이썬 리스트에 저장
stations = [station_0, station_1, station_2, station_3]
# 노드들을 해시 테이블에 저장 -> 이렇게 하면 좀 더 직관적으로 노드들을 가져올 수 있음
stations2 = {
"교대역": station_0,
"사당역": station_1,
"종로3가역": station_2,
"서울역": station_3
}
node_1 = stations2['교대역']
node_2 = stations2['서울역']
# 이 방법을 쓸 때는 조심해야 되는게, key-value를 저장하는 해시 테이블 특성 상 key가 겹치면 안된다는 제약이 있다. 지금은 지하철역들이 같은 이름을 갖는 두 개의 역이 없어서 지하철 역 이름을 key로, 지하쳘 억 노드를 value로 사용해서 노드를 저장할 수 있었다.
# 이름을 key로 써서 해시 테이블에 저장하고자 한다면, 겹치는 이름이 너무 많아서 저장할 수가 없기 때문에 이메일 주소처럼 개인마다의 고유한 이메일을 key로 지정해야 한다.
노드들을 파이썬 리스트로 저장하면 station[3] 이런 식으로 서울역 노드를 O(1)로 효율적으로 받아올 수 있다.
한 편, 노드들을 해시 테이블에 저장한다면
node_1 = stations2['교대역']
node_2 = stations2['서울역']이런 식으로 노드들을 좀 더 직관적으로 가져올 수 있는데, 이 방법을 쓸 때는 조심해야 할 점이 있다. key-value를 저장하는 해시 테이블 특성 상 key가 겹치면 안된다는 제약이 있다. 지금은 지하철역들이 같은 이름을 갖는 두 개의 역이 없어서 지하철 역 이름을 key로, 지하철 역 노드를 value로 사용해서 노드를 저장할 수 있었다.
이름을 key로 써서 해시 테이블에 저장하고자 한다면, 겹치는 이름이 너무 많아서 저장할 수가 없기 때문에 이메일 주소처럼 개인마다의 고유한 이메일을 key로 지정해야 한다.
엣지 구현 I: 인접 행렬

이 친구관계 그래프를 구현하고자 한다고 해 보자. 각 노드에 인덱스 표시가 되어 있다.

인접했다는 말은, 두 노드 사이에 엣지가 있어서 연결이 되어 있다는 뜻이다. 행렬은, 2차원 배열 혹은 2차원 리스트이다. 인접해 있을 경우 1로, 인접해있지 않을 경우 0으로 표시한다면..

이렇게 행렬이 0과 1로 채워지게 된다. 엣지들 사이에 가중치가 있다면, 그 가중치 값을 1 대신에 적어주면 된다.
방향 그래프의 경우, 1 -> 0 인 경우, 1에서 0으로의 표시는 1행 0렬에 나타나지만, 0에서 1로는 가지 않기 때문에 0행 1렬엔 아무것도 없다.

대각선을 기준으로 대칭적이지 않다.
정리해보면, 인접행렬은
- 각 노드를 리스트에 저장해 고유 정수 인덱스를 준다
- 노드 수 * 노드 수 크기의 행렬을 만든다.
- 노드들의 엣지 유무 및 가중치에 따라 행렬의 요소를 채운다.
엣지 구현 II: 인접 리스트

위의 역들을 파이썬 리스트로 구현한다고 해 보자. 이 경우 그냥 station['강남'] 이런식으로 가져오면 될 것이다.

인접 리스트는, 노드들의 인접 데이터를 리스트에 저장하는 방법이다.
class StationNode:
"""지하철역 노드를 나타내는 클래스"""
def __init__(self, name, num_exits):
self.name = name
self.num_exits = num_exits
self.adjacent_stations = [][stations['교대'], stations['역삼'], stations['양재']]에 이제 adjacent_stations를 통해 강남이 추가가 되는 것이다.
그래프 노드가 연결된 노드들에 대한 레퍼런스를 저장한다.
무방향 그래프의 경우: A - B일 때, A의 인접 리스트에 B를 넣어야 하고 동시에 B의 인접 리스트에 A를 넣어야 한다.
방향 그래프의 경우: A를 떠나 B로 향하는 엣지가 있으면, A의 인접 리스트에는 B를 넣고, B의 인접 리스트에는 A를 넣지 않는다. 즉, 엣지가 떠나는 노드의 인접 리스트에만 엣지가 들어가는 노드를 넣는 것이다.
가중치 그래프의 경우: A - B이고, 가중치가 4일 때, A의 인접 리스트에는
[(B, 4)]를 넣고, B의 인접 리스트에는[(A, 4)]를 넣으면 된다.
저장하면 인접 리스트는:
- 각 노드마다 스스로 인접한 노드들에 대한 레퍼런스를 저장해서 엣지를 구현하는 방법인 것이다.
인접 행렬 vs 인접 리스트
이 두 방법을 사용했을 때 공간과 시간을 얼마나 효율적으로 사용할 수 있는지를 알아보자.
복잡도 표현 기호
다른 자료 구조들을 공부할 때는 들어있는 데이터 수를 n이라고 했는데, 그래프를 분석할 때는 다른 알파벳들을 쓴다.

첫 번째는 V이다. V는 그래프 안에 있는 모든 노드들의 집합이다. 그래프에 있는 하나의 데이터 객체를 노드라고도 부르지만, Vertex라는 표현을 사용하기도 하는데, Vertex의 가장 앞 알파벳을 따서 V라고 하는 것이다.
두 번째는 E이다. E는 그래프 안에 있는 모든 엣지들의 집합이다. Edge의 가장 앞 알파벳을 따서 E를 사용한다.
원래 V와 E는 노드와 엣지의 수를 나타내는 건 아닌데, 점근 표기법에서 사용할 때V는 모든 노드의 수, 그리고 E를 모든 엣지의 수로 사용하기도 한다. 위에서는 V도, E도 모두 6인 것이다.
V와 E의 관계에 대해 알아볼 점이 있다. 노드 수가 V일 때 그래프 안에는 최대 몇 개의 엣지가 있을 수 있을까? 모든 노드가 서로 다른 모든 노드에 연결되어 있는 경우가 엣지가 가장 많을 때이다. 이때 무방향 그래프는 V^2/2, 방향 그래프는 V^2개의 엣지를 갖는다. 두 경우 모두 V^2에 비례하는 만큼의 엣지를 가질 수 있는 것이다. 그렇기 때문에 E는 최악의 경우 V^2에 비례한다.
그래프를 배울 때는 O(n), O(log(n)) 이런 점근 표기법 대신 O(V), O(E), O(log(V)) 이렇게 표시를 하기 때문에 낯설게 느껴질 수 있지만, 그냥 n 대신 다른 알파벳을 사용하는 것 뿐이다.
노드를 저장하는 공간
일단 인접 행렬이든 인접 리스트이든 사용하려면 노드를 저장해야 되는데, 노드의 개수를 V로 나타낸다고 했다. 총 V개의 노드를 저장하기 때문에 노드를 저장하는 데는 O(V)의 공간을 사용한다고 할 수 있다.
인접 행렬이 차지하는 공간
인접 행렬이 차지하는 공간에 대해 생각해 보자. 인접 행렬은 총 노드의 수 * 총 노드의 수 만큼의 행렬을 만들었다. 그러므로 총 노드가 5개일 때 5 x 5 크기의 행렬을 만들었다. 그리고 여기에 노드들 간의 인접 데이터를 저장했다. 두 노드가 인접했을 때 1, 아닐 때 0을 저장했다.
이를 이용해서 인접 행렬이 사용하는 공간에 대해 한 번 생각해보자. 그래프 안에 있는 노드의 수가 V라고 할 때 인접 행렬은 V * V 크기의 행렬을 저장하고 각 요소들이 0 또는 1을 저장했는데, 그럼 총 V^2개의 정수를 저장한 것이다. 그렇기 때문에 인접 행렬은 총 V^2에 비례하는 공간, 즉 O(V^2)의 공간을 사용한다.
인접 리스트가 차지하는 공간
인접 리스트는 얼마만큼의 공간을 사용할까? 인접 리스트는 각 노드가 자신과 인접한 노드들을 가리키는 레퍼런스를 저장하고 있다. 일단 모든 노드는 하나의 인접 리스트를 갖는다. 그러니까 총 V개의 배열 또는 파이썬 리스트를 저장해야 되는 것이다. V에 비례하기 때문에 일단 최소 O(V)만큼의 공간을 차지하는 것이다.

그럼 엣지를 저장하는데는 얼만큼의 공간을 사용할까? 모든 노드에 저장된 엣지 데이터를 다 합치면 무방향 그래프일 때 2E, 방향 그래프일 때는 E이다(무방향 그래프는 똑같은 엣지를 2개씩 저장하기 때문이다). 총 저장하는 레퍼런스 수는 E에 비례한다고 할 수 있다. O(E)이다.
이걸 합쳐보면, 인접 리스트 자체를 저장하는 데 O(V), 엣지를 저장하는데 O(E)를 사용하기 때문에 총 O(V + E)를 사용한다. V와 E, 둘 중 어떤 게 더 큰 지는 알 수 없기 때문에 두 알파벳 중 하나를 골라서 그것만으로 점근 표기법을 쓸 수는 없고 그냥 O(V + E)만큼의 공간을 사용한다고 표현한다.
그럼에도 불구하고 E는 최악의 경우 (모든 노드가 서로 다른 모든 노드에 연결됐을 경우) V^2에 비례한다고 했었다. 그렇기 때문에 O(V + E)라고 볼 수도 있지만 E = O(V^2)라는 최악의 경우를 생각하면 인접 리스트도 O(V^2)의 공간을 차지한다고 할 수 있다.
하지만 좀 더 공간 복잡도를 현실적으로 표기하기 위해서 주로 O(V + E)라고 한다.
두 노드가 연결됐는지 확인하는 데 걸리는 시간
인접 행렬을 이용하면 두 노드가 인접했는지 아닌지를 O(1)으로 알아낼 수 있다. 예를 들어 3에 해당하는 노드와 5에 해당하는 노드가 서로 인접해 있는지 알고 싶다고 해 보자. 그럼 adjacency_matrix[3][5] 이런 식으로 인덱스를 사용하면 바로 알아낼 수 있다.
인접 리스트는 어떨까?
gangnam_station = stations["강남"]
seocho_station = stations["서초"]
print(seocho_station in gangnam_station.adjacent_stations)이런 식으로 한 노드의 리스트 안에 특정 역에 저장됐는지를 탐색해야 한다. 선형 탐색을 해야하기 때문에 리스트 안에 있는 데이터를 다 돌아야 한다. 몇 개의 데이터가 있는지에 따라 다르겠지만 최악의 경우 V개의 요소를 확인해야 되는 것이다.
한 노드에 연결된 모든 노드들을 알아내는데 걸리는 시간
그래프를 사용할 때 주로 한 노드에 연결된 모든 노드들을 갖고 오는 작업을 많이 하게 될 것인데, 그럼 이 작업을 할 때는 어떤 방법을 사용하는 게 좋을까?
인접 행렬을 사용할 때 이 작업을 할 때는 시간이 얼만큼 걸리는지 생각해보자. 인접 행렬에서는 한 노드를 나타내는 배열, 또는 파이썬 리스트 전체를 다 돌아야지만 그 노드가 연결된 다른 노드들을 갖고 올 수 있다. 그러니까 리스트 안에 있는 데이터를 하나씩 돌면서 0인지 1인지를 확인해야 되는 것이다. 모든 리스트 안에는 총 V개의 데이터 요소가 들어 있으니까 매번 V번 돌아야 되는 것이다.
인접 리스트를 쓸 때는 각 노드가 자신과 인접한 노드들에 대한 레퍼런스만 갖고 있다. 물론 최악의 경우 한 노드가 다른 모든 노드들과 연결돼 있으면, 인접 행렬과 마찬가지로 총 V번 돌아서 인접한 노드들을 가지고 와야되긴 한데, 이런 경우는 그렇게 많지 않다. 대부분의 경우 인접 행렬을 사용하는 거보다 더 빨리 실행된다.
따라서 보통의 경우는 인접 리스트가 더 빠르다.
출처: 코드잇
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] BFS 알고리즘 (0) | 2021.03.09 |
|---|---|
| [자료구조] 이진 탐색 트리(2) (삭제, 시간 복잡도) (0) | 2021.03.04 |
| [자료구조] 이진 탐색 트리(1) (탐색, 삽입, 삭제) (0) | 2021.03.02 |
| [자료구조] 힙, 우선 순위 큐 (0) | 2021.03.02 |
| [자료구조] 트리 (0) | 2021.02.22 |
